Interpreting Tables 2 & 3

It is clear to me that credibility in experience rating methods is inversely related to the intra-class variance (i.e., the VHM: Variance of the Hypothetical Mean). This was a take-away from the Fisher experience rating reading, and is reiterated again in Bailey & Simon. We could also use the Bühlmann Credibility formula to provide further proof of this fact. However, I keep re-reading this paper and my current understanding is sensing some contradictory statements that have me pausing to better understand.
Bailey & Simon make the following 2 statements:
Quote 1) "Classes 2, 3, 4 and 5 are more narrowly defined than Class 1 ... [ and we confirm using 3yr Credibility - to - Frequency Ratios] the expectation that there is less variation of individual hazards in those classes"
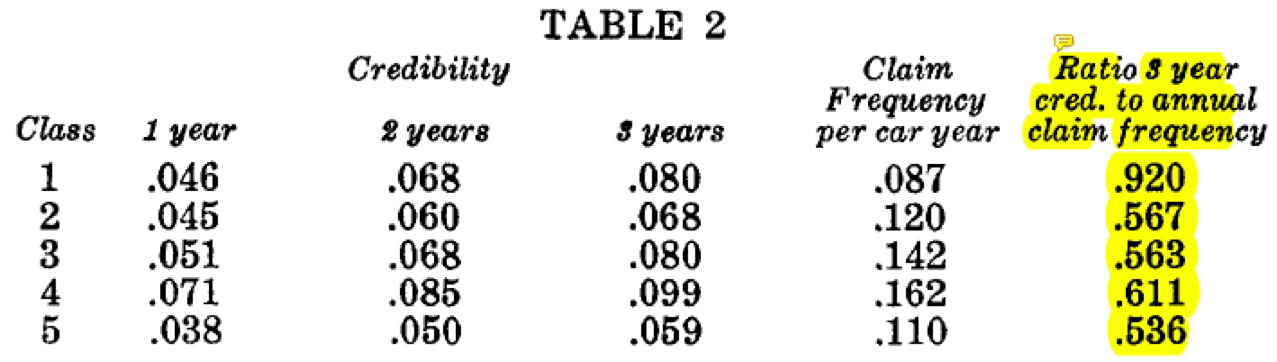
To me, the conclusion is very clear: More refined classes produce smaller marginal changes in credibility for a unit change in claim exposure (frequency). This agrees with my original understanding.
Quote 2) "The fact that the relative credibilities in Table 3 for two and three years are much less than 2.00 and 3.00 is partially caused by risks entering and leaving the class. But it can be fully accounted for only if an individual insured's chance for an accident changes from time to time within a year and from one year to the next, or if the risk distribution of individual insureds has a marked skewness reflecting varying degrees of accident proneness." [emphasis added]
I read this as saying that evidence of uncontrolled variation within the rating class gives reason for the relative credibility being much less than 3.0 and 2.0, which essentially means credibility exhibits less sensitivity to additional years exposure.
With this said we might infer that Class 1, which is noted to have the most intra-class variance, would show the LEAST spread in relative credibility ratios (further from 3.0 and 2.0). Contrary to this logic, we see in Table 3 that Class 1 shows the greatest sensitivity to additional years of experience and is closest to 3.0 and 2.0 compared to other classes:
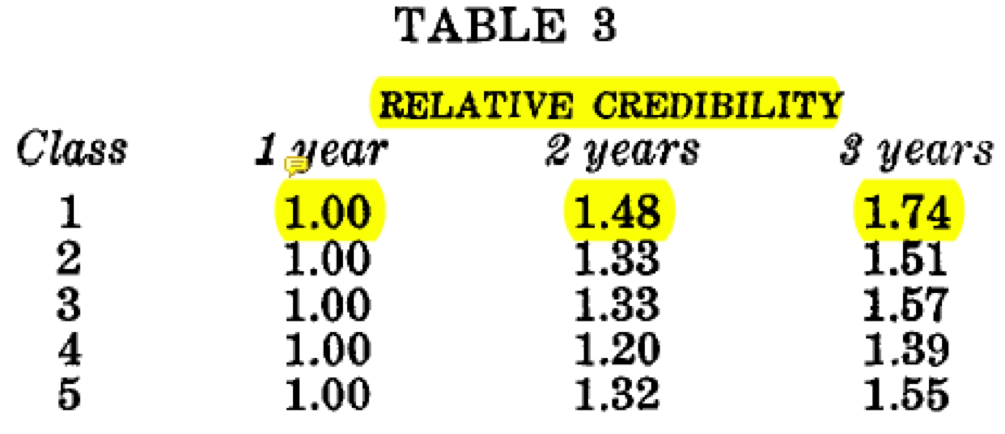
I see the trend in Table 3 above, and it looks exactly as I would expect. Namely, classes with the most intra-class variance will be MOST sensitive to a marginal increase in exposure (years experience in this case), just as was the case in Table 2 in response to a marginal increase in exposure (via claims frequency). Does this contradict the message from Quote 2 above, in that uncontrolled variation within a class should cause the relative credibilities to be lower (further from 3.0 and 2.0)?
I want to trust that the authors have not contradicted themselves, so figure I am missing something in my interpretation of the paper.
Another place where I began suspecting I was missing a detail was in attempting CAS 2011 Q1. I observed that Territory X shows greater indicated spread in experience modification (and relative credibilities). Borrowing again from the lesson from Fisher Experience Rating, I thought that greater significance of experience modifications would be observed in a portfolio with a less refined rating scheme (or simply more variation in the portfolio of risks). The answer indicates that Territory Y actually has greater variation in an individual insured's probability of an accident, which is the opposite of what I had at first suspected. Could someone help clarify where my logic breaks down?
Thank you.
Comments
I believe the piece you are missing here is that Table 2 - 3 years credibility refers to policies with merit rating group A only (at least 3 years claims free).
The broad picture from both Bailey & Simon and Fisher is the more variation within a rating class, greater credibility may be assigned to the individual risk experience relative to the class average. So adding more years of data for a refined class produces less of an increase in credibility than if you added more years of data to a relatively unrefined class such as class 1.
The additional variation within a class that the authors refer to is over time a risk may remain within class i but change merit rating group either through incurring an accident or gaining additional years of being claims free. It is this variation, that as we add more years we get more risks changing within the class which causes the gain in credibility to be less than expected. This is in addition to risks moving class, i.e. someone who was under 25 for part of the experience period turns 25 and ages into a different class.
Regarding 2011 Q1 I think you may be confusing the trends and dispersion in the manual and standard loss ratios with the experience mod. Remember, the experience mod serves to describe how well the risk fits within the rating classification. An experience mod materially different from 1.000 just means the risk isn't a good fit for the class. It is the relative experience between the risks in the class that imply how volatile the class is. Since we have more knowledge about risks in merit rating group A than groups A+X (3 vs 2 years claim free know), if the experience was stable we expect the increase in relative credibility to move from about 2 to about 3. This is what we see for state X but not state Y, so risks in state Y have more individual volatility from year to year.
Thank you. I think I'm able to see this as distinguishing the effects of both Process Variance and Variance in the Hypothetical Class Mean.
Class 1 in Bailey & Simon looks more like Territory X, and Classes 2-5 more like Territory Y (relatively speaking). Based on the logic for 2011 Q1, would we then infer that Class 1 in Bailey & Simon has less individual volatility (process variance) from year to year than classes 2-5, despite being a less refined class with greater than average VHM? Given our knowledge of what Class 1 contains, and the relative size of the class, this is likely a reasonable conclusion, but on the exam (ex 2011 Q1) we may not have such background information to validate our conclusions.
An increase in VHM leads to greater positive sensitivity of credibility to additional years exposure, but differences in Process Variance have the opposite effect (more volatile insurance categories will have less credibility given to historic experience). Given the counteracting effect of the two sources of variation, can we reliably comment on whether differences in relative credibility between portfolios is driven predominantly by one versus the other?
I'm using Bühlmann Credibility as a demonstrative example, Z=na/(na+v)=n/(n+K), where a=VHM v=EPV (K=v/a is Bühlmann's K). Taking ratios, we would get:
Of course Bühlmann credibility assumes normality and is a linear approximation, but I think the math is still instructional concerning the interacting factors at play here. It is too lengthy a discussion to get into how a & v may or may not vary between population 1 & k (A+X+Y vs just A for instance), and the relative balance between EPV & VHM (Buhlmann's K) would also vary by example. Regardless, I'm not sure any of that sends me to a universal conclusion to say that the relative credibility can be directly attributable to relative differences in just one of VHM or EPV.
If we compare RZ between portfolios X and Y, there could be scenarios where the EPV is identical between the two, and differences in RZ purely due to portfolio class refinement (VHM). Likewise, VHM could be identical and differences in EPV prevail.
Maybe this observation is part of the reason behind the criticism offered by Hazam. However, it still leaves me at odds reconciling my own thoughts to ensure I don't accidentally make an argument on an exam question that goes against the prevailing opinion of the paper. For example, what keeps one from proposing in 2011 Q1 that Territory X & Y might have equal process variance, and Territory X is simply a less refined territory with greater VHM than Territory Y which we can see when partitioning by Yrs Claim Free? This hypothesis, if applied to the text example, would have accurately pegged Class 1 as having greater than normal VHM compared to say Class 4. Would it be a true conclusion all of the time? Probably not, but the competing alternative likely wouldn't be either if I understand correctly.
Forgive me if I am still missing the point... I am just trying to fully convince myself exactly why the competing interpretation is incorrect, knowing that there will only be 1 correct interpretation on exam day.
Thanks again.
You raise excellent, well considered arguments that are probably a bit too deep for what appears to be a lesser syllabus exam reading. Your comments certainly seem to follow Hazam's logic regarding maldistribution. In 2011 Q1 we are using earned premiums at present group D rates which should hopefully control for differences in territory refinements - assuming the territories are adequately priced. With this simplification, we can focus on the difference in process variance between territories. More stable territories should have lower process variance and hence greater credibility.
I might be wrong, but I would have thought territory factors simply shift the average premium to match the Territory's hypothetical mean, but would have little influence on the extent of variance remaining around this hypothetical mean (refinement of the class). The sophistication of the overall classification system, and its performance within a given territorial subsegment would determine the magnitude of VHM.
Anyway, you are right. This is getting way too deep for its worth in terms of the exam; a shame that exams force us to think like that... but it is what it is. Thank you again for the feedback.
I think the point I was trying to make is the earned premiums should account for other differences between risks across territories - such as one territory favoring younger drivers than others. The territory factor itself shifts the average premium but we'd (now at least) rate on more than territory alone.
I like how you're trying to draw parallels with other exam questions - that's a great way to strengthen your skills for the integrative questions. One thought for comparing territories to states is territories are usually within the same rating plan, while states often have their own rating plans with separate characteristics/quirks such as minimum liability limits etc. So using earned premiums is a good idea when working with territories so long as we meet Hazam's criteria.
Keep up the good work!